Let's be honest — running SAP is like conducting a symphony of moving parts that never stop playing.
Jobs, dumps, queues, interfaces, databases — something is always happening.
Now imagine if your SAP system could quietly fix its own problems while you're asleep.
No pager buzz. No panic. Just… Click. Heal. Repeat.
That's not a fantasy anymore.
Thanks to open-source AI and automation, SAP landscapes are becoming smart enough to
detect,
decide, act, and learn — all on their own.
The End of “Oh No, Another Alert”
For years, SAP Basis and Ops teams have been firefighting the same stuff: a failed background job
here, a locked queue there, maybe a HANA memory spike for good measure.
We built scripts, dashboards, and ticket workflows — but none of it truly understood what was going
on.
Monitoring told us what happened. Logs told us when. But nobody told us why — or how to stop it from
happening again.
That's where AI reasoning + open-source automation come together.
It's not about replacing people; it's about building systems that can take care of themselves, so we
can focus on what actually matters — improving, not just maintaining.
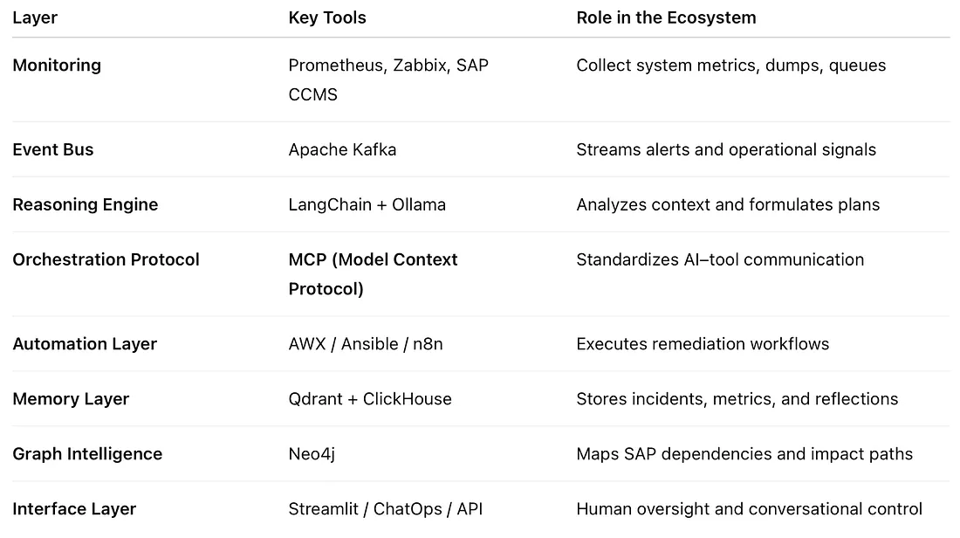
The Open Source AI Stack Behind Self-Healing SAP
The foundation of this new paradigm is 100% open source — modular, transparent, and vendor-neutral.
Put these together and you've basically got a digital immune system for SAP — one that learns,
reacts, and improves over time.
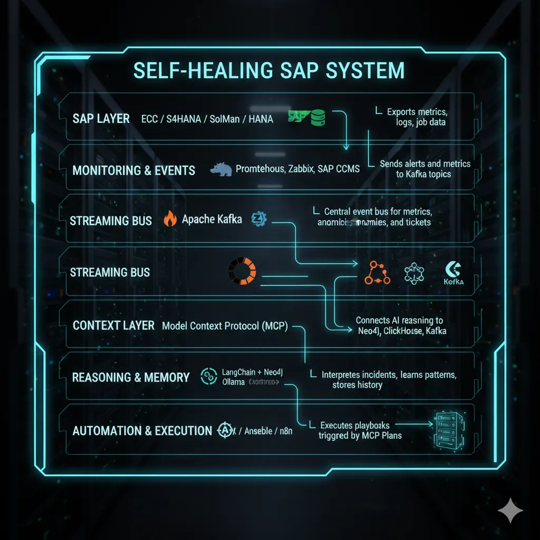
How It Works — The Self-Healing Lifecycle
Let's walk through how this architecture transforms an ordinary SAP landscape into a living,
learning system.
Step 1 — Monitoring Detects an Anomaly
Prometheus or Zabbix spots it instantly — maybe a batch job dumped or a HANA node spiked CPU.
Instead of emailing you at 3 AM, it sends an event to Kafka (our trusty message bus)
Step 2 — Kafka Streams the Event to the MCP Layer
Kafka hands that event off to
MCP, the AI's translator.
MCP looks at the situation, pulls historical data from
ClickHouse, and checks
Neo4j to
see what other systems might be affected.
It then packages all of that into a neat, AI-readable “context” and hands it to
LangChain +
Ollama.
Step 3 — The AI Thinks It Through
The model looks at the data and goes:
“Oh, I've seen this before. When RFC queues block like this, clearing SMQ1 usually helps.”
It builds a plan in JSON — literally an instruction list like:
{
"plan": [
{"tool": "query_clickhouse", "params": {"query": "select * from job_failures where
system='S4P01'"}},
{"tool": "launch_awx_job", "params": {"template": "Clear_SMQ1_Queue"}},
{"tool": "update_neo4j", "params": {"relation": "auto_healed"}}
]
}
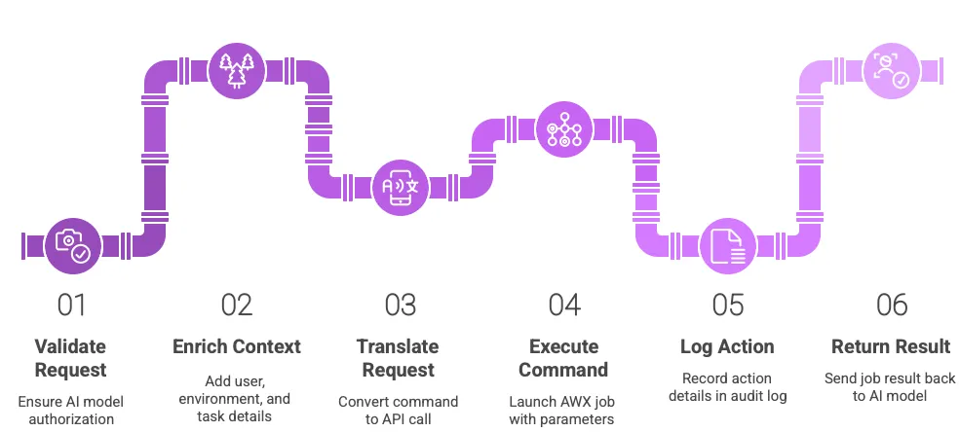
Step 4 — The Fix Happens (Safely)
MCP executes each step:
AWX runs the Ansible playbook, clears the queue, and confirms the job's healthy again.
Prometheus sees the recovery, Kafka logs the success, and ClickHouse stores the event.
Step 5 — The System Learns
The context and outcome get saved in Qdrant as a “memory.”
Next time something similar happens, the AI recognizes it instantly — and fixes it even faster.
That's the magic: every loop makes the system smarter.
MCP — The Secret Sauce Holding It All Together
Here's the thing: AI models don't naturally know how to talk to systems like AWX or Neo4j.
That's where MCP (Model Context Protocol) comes in.
It's basically a universal language that lets AI safely call real-world tools — like “launch this
AWX job” or “query this ClickHouse table” — without hardcoding APIs or risking chaos.
MCP keeps everything:
-
Contextual (it knows what the AI is doing and why)
-
Governed (every action is logged and scoped)
-
Repeatable (same plan works in dev, test, and prod)
In short: MCP makes AI trustworthy enough for SAP production.
Kafka — The Always-On Messenger
If MCP is the translator, Kafka is the courier.
It's the real-time bus that moves alerts, actions, and reflections across the ecosystem.
1 - When Zabbix sees an issue, it posts to Kafka.
2 - When AWX finishes a fix, that result also goes to Kafka.
3 - The AI reads those messages like a continuous stream of context — learning the “heartbeat” of
your SAP landscape.
You can even replay Kafka topics to rebuild an incident timeline or simulate past conditions.
It's like having an infinite DVR for your IT operations.
ClickHouse — The System's Long-Term Memory
ClickHouse is where the AI stores its wisdom.
Every alert, metric, and fix gets logged — forever — and can be queried in milliseconds.
That means the AI doesn't just react to this issue — it compares it with hundreds of past ones:
“This dump looks like the one from last Friday — same root cause, same solution.”
ClickHouse turns raw events into insight.
And because it's blazing fast at time-series queries, it can spot patterns like:
“CPU spikes every Tuesday at 2 AM.”
“These job failures only happen after patch runs.”
Knowledge → Context → Prediction. That's the evolution.
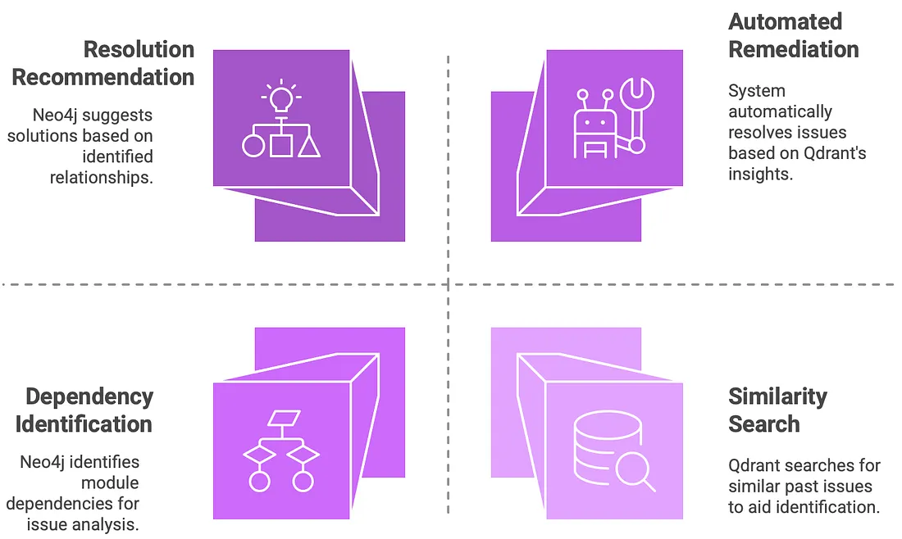
Neo4j & Qdrant — The Brain's Map and Memory
Two more crucial pieces:
Neo4j and
Qdrant.
Neo4j builds a graph of your SAP world — which system talks to which, what depends on what.
When something breaks, it can tell you who else gets hurt.
Qdrant stores semantic memory — not just “errors,” but the meaning behind them.
Logs, tickets, and resolutions get turned into vector embeddings, so the AI can find similar
situations fast.
Together, they give your self-healing system both contextual awareness and pattern memory.
Neo4j shows the structure; Qdrant recalls the stories.
AWX & n8n — The Hands That Do the Work
Once the AI decides what to do,
AWX and
n8n get it done.
AWX handles the technical side — running Ansible playbooks to restart instances, clear queues,
extend filesystems.
Example AWX playbook triggered via MCP:
- name: Clear SMQ1 Queue
hosts: sap_hosts
tasks:
- name: Run SAP command to clear SMQ1
command: "sapcontrol -nr {{ instance_nr }} -function ClearQueue
SMQ1"
n8n handles orchestration — approvals, notifications, Slack messages, Jira tickets.
For example:
“AI fixed the failed billing job on S4P01 at 2:14 AM — verified success.”
That message? It came from an
n8n flow triggered after
AWX finished healing.
No human involved, no time wasted.
No matter how advanced automation becomes, trust is everything.
The
Click–Heal–Repeat model keeps humans in control through MCP's built-in
governance:
- Action Scopes: restrict AI actions to non-critical systems or predefined playbooks
- Plan Approvals: certain plans require human validation before execution
- Explainable Logs: every AI decision includes a natural-language summary logged in
ClickHouse
Example AI reflection logged:
“Restarted job FI_DOC_POSTING due to memory overflow on system S4H01. Similar issue fixed
successfully 3 times in past 60 days.”
Operators can approve or override at any point — ensuring safety without sacrificing speed.
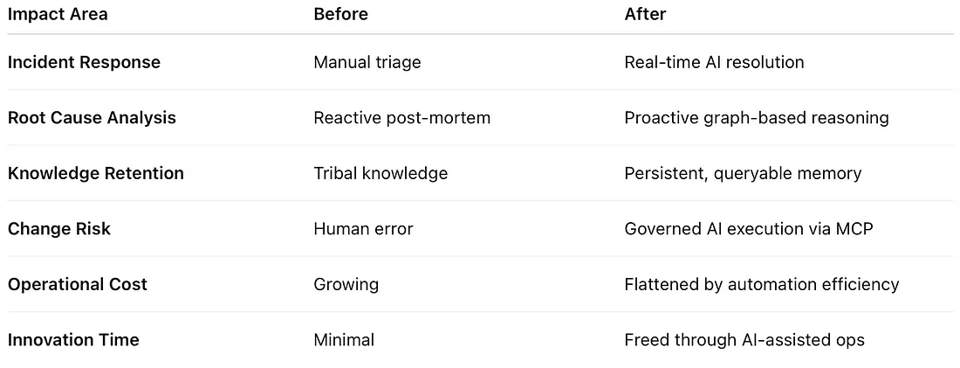
Business Impact — Beyond Uptime
Implementing this model doesn't just fix incidents — it transforms operations.
This is not a technology story — it's an
organizational transformation.
Self-healing SAP systems empower teams to focus on
architecture, creativity, and strategy,
not repetitive maintenance.
In the next few years,
AI-driven operations will become as normal as system monitoring is
today.
SAP environments will operate with
built-in cognition — not just logging issues, but
understanding them.
Open-source AI frameworks, streaming backbones, and graph intelligence will blur the line between human and machine expertise.
“Your SAP system will not just run — it will reason.”
And when it does, uptime becomes creativity time.
That’s the real promise of
Click. Heal. Repeat.